

Ein großer deutscher Fabrikausrüster berichtete kürzlich über seine eigene Fertigung: Durch den Einsatz künstliche Intelligenz (KI) lassen sich dort pro Jahr zwischen 1 und 2Mio.€ sparen. So wurde beispielsweise die Taktzeit um 15 Prozent gesenkt, in dem durch KI Störungen in den Prozessabläufen identifiziert und beseitigt wurden. Dabei ist zwar oftmals von KI die Rede, gemeint ist jedoch maschinelles Lernen (ML). Was ist der Unterschied? Künstliche Intelligenz bezeichnet primär alle Technologien, die menschliche Intelligenz nachahmen. Das Maschinelle Lernen ist eine Teildisziplin dessen – weil hier das Erlernen und Anwenden des Gelernten nachgeahmt wird. Beim ML erlernen Maschinen mit Hilfe von großen Datenmengen selbständig Aufgaben zu lösen. Noch spezifischer wird diese Disziplin wiederum im Deep Learning ausgeprägt. (Abbildung 1). Daraus ergeben sich oftmals zwei Missverständnisse.
- Erstens: künstliche Intelligenz löst alle Probleme quasi automatisch
- Zweitens: dadurch lassen sich signifikant Personalkosten sparen, da die Maschinen intelligent genug sind, um alles selber zu erledigen.
Missverständnis 1
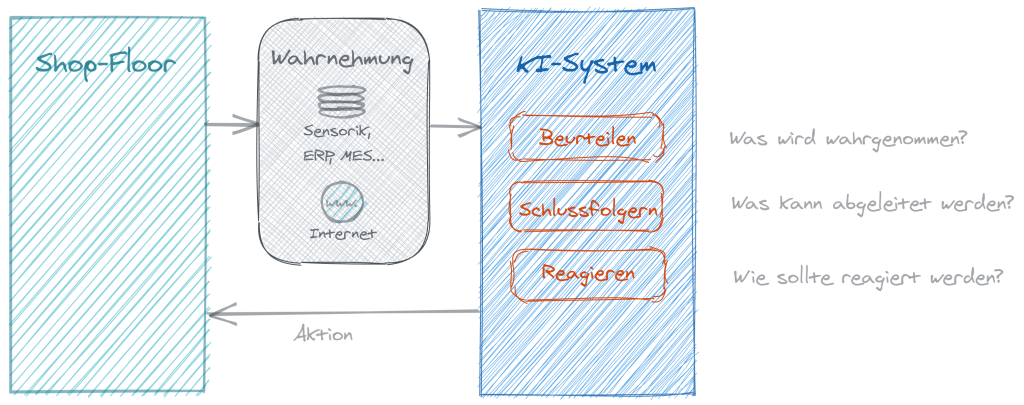
Das erste Missverständnis lässt sich mit ‚garbage in – garbage out‘ klären. KI ist nicht von alleine intelligent, sondern lernt mittels ML aus vorhandenen Daten. Sind diese Daten qualitativ schlecht, wird es auch falsch nachgemacht. Der Algorithmus ist ein mathematisches Modell, welches aus dem Gelernten entstanden ist und per se erst einmal weder gut noch schlecht. Daher sollte ein Algorithmus, der aus dem ML entsteht keine ‚Black Box‘, sondern nachvollziehbar sein. Dabei hilft eine grobe Skizze. Ein KI-System funktioniert im Prinzip auf drei Ebenen: Was nehme ich war? Was kann ich ableiten? Wie muss ich reagieren? Die Wahrnehmung passiert über Sensorik, also Bewegungsdaten, und Stammdaten. Als Ergebnis wird dann wiederum eine Aktion zurückgespielt. Eine entscheidende Fähigkeit von KI-Systemen ist also, auf Basis von Daten Rückschlüsse auf den Zustand im Shopfloor – beispielsweise einer Maschine – ziehen zu können. Neben der Beurteilung können Unternehmen durch datenbasierte Methoden auch neue Erkenntnisse zu gewinnen. Prognosen liefern beispielsweise zusätzliche Informationen für die Entscheidungsfindung. Durch direkte Interaktion mit dem Shopfloor oder einem intelligenten Produkt können KI-Systeme lernen, welchen Einfluss bestimmte Aktionen hatten und welche Aktionen in Zukunft ausgeführt werden müssen, um ein bestimmtes Ziel zu erreichen. Somit löst KI nicht von Geisterhand alle Probleme, sondern wird explizit und begleitet für eine spezielle Problemlösung eingesetzt. Entweder, um eine Fabrik intelligenter zu gestalten oder neue Geschäftsmodelle zu etablieren. Der Schlüssel ist der Prozess, nicht die Technik.

Missverständnis 2
Wer, wie bereits angesprochen, KI einsetzen möchte, um Personalkosten zu sparen, sägt am falschen Ast. Zumal der Fachkräftemangel ohnehin ein Problem ist. Entscheidender ist es, die eigenen Prozesse so im Griff zu haben, dass sie gleichzeitig effizient und flexibel bzw. agil sind. Bis zu 70 Prozent der Kosten stecken verdeckt in Prozessen, die bisher aufgrund fehlender technischer Möglichkeiten nicht sichtbar gemacht werden konnten. Bei der Identifizierung dieser Kostentreiber kann Datenintelligenz ebenfalls helfen. Beispiele dafür sind Predictive Analytics, Predictive Quality oder die prozessübergreifende Visualisierung von Schwachstellen mit Hilfe von Process Mining. Dabei handelt es sich um eine KI-basierte Technik, die Geschäftsprozesse übergreifend auf Basis digitaler Spuren in IT-Systemen rekonstruieren und auswerten kann.
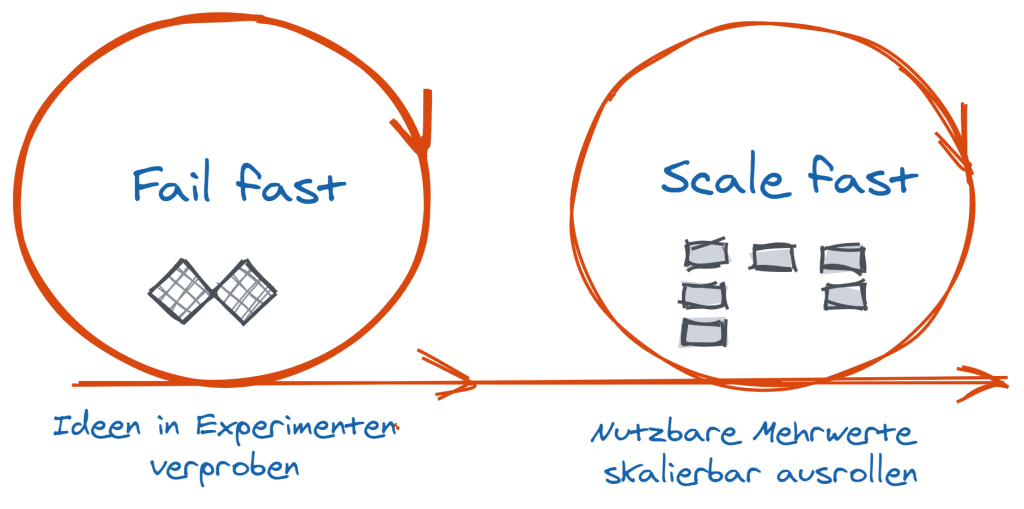
Fail fast, Scale fast
Ist die Berührungsangst mit künstlicher Intelligenz, Machine und Deep Learning erst einmal abgefallen, gilt es Erfahrungen zu sammeln. Das Vorgehen erfolgt idealerweise in zwei Schritten: zunächst in Experimenten schnell die unvermeidbaren Fehler machen (fail fast) und dann die erfolgreichen Experimente produktiv ausrollen (scale fast). Dabei muss ein erfolgreiches Experiment nicht das Projektergebnis sein, sondern oftmals schon ein Teilerfolg innerhalb eines Projektvorgehens. n bei Trebing + Himstedt.