

In den meisten Produktionsbetrieben ist KI heute noch nicht angekommen, doch viele Firmen arbeiten bereits fieberhaft an den ersten Anwendungen. Dabei ist vor allen Dingen ein Parameter von höchster Bedeutung: Stabilität und Reproduzierbarkeit. Nicht alles was die KI auf den ersten Blick verspricht kann sie auch halten. Vor allen Dingen, wenn fehlerhafte Daten bzw. nicht ursächlich mit der Anwendung in Zusammenhang stehende Muster in den Daten Eingang in das Vorhersagemodell der KI finden. Aber was ist der Vorteil, das eigentliche Versprechen der KI? KI, insbesondere Deep Learning, ist in der Lage Zusammenhänge in Daten zu erkennen, Merkmale und Muster zu extrahieren wie es bis dato kein Mensch und Expertensystem zu bewerkstelligen vermag. Der technologische Fortschritt besteht für die Industrie letztlich darin, dass KI-Systeme in einem komplexen Produktionsprozess anhand diverser Sensor- und Maschinendaten qualitäts- und performancerelevante Korrelationen entdecken, die bisher viel Erfahrung des menschlichen Betreibers benötigten oder sogar gänzlich unbekannt bzw. ungenutzt waren.
Hyperspectral Imaging
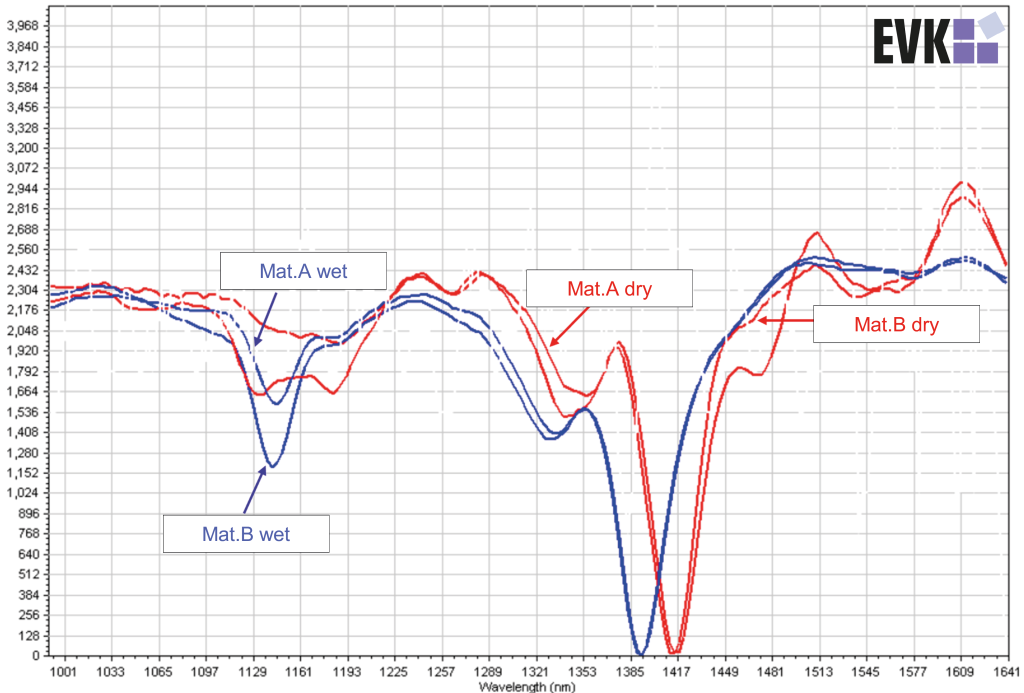
Dies gilt auch für die Anwendung von Deep Learning auf Hyperspektraldaten. Letztere sind hochdimensionale (>100 Wellenlängenbänder je Pixel) Bilddaten mit entsprechend hoher Informationstiefe über die chemische Zusammensetzung von Materialien. Ideal geeignet, um die Vorteile der KI und ihrer Fähigkeit komplexe Zusammenhänge zu erkennen, zu nutzen. Dies zeigen auch erste Feldversuche von EVK, einem hochspezialisierten Mittelständler aus Österreich, der seine Lösungen mittels Hyperspektraler und Induktiver Bildverarbeitung im Bereich sensorgestützte Sortiertechnik und Monitoring anbietet. So konnten unter Verwendung von Deep Learning Sortiertiefen von Abfällen jenseits der 90% erreicht werden, während klassische Algorithmen mit den gleichen hyperspektralen Sensordaten höchstens eine 80%-ige Genauigkeit schaffen. Dies deutet darauf hin, dass die KI auf (zusätzlichen) spektralen Merkmalen aufbaut, derer herkömmliches maschinelles Lernen offenbar nicht habhaft wird. Diesen Sachverhalt kennt man bereits aus dem Bereich Objekterkennung in der Bildverarbeitung wo die extrahierten Merkmale der ersten Layer von tiefen Netzwerken bekannten Eigenschaften wie z.B. Kanten und Texturen entsprechen, jene in tieferen Schichten liegenden für den Menschen aber keinen augenscheinlichen Sinn mehr ergeben. Diese zusätzlichen Merkmale, die das Netzwerk automatisch lernt, machen den Erfolg der KI aus. Wesentlich dabei ist jedoch deren Stabilität. Denn das Netzwerk kann im Lernprozess nicht zwischen kausalen und damit echten Korrelationen und systematischen Fehlsignalen unterscheiden. Daher ist es auch bei der Hyperspektralen Bildgebung wesentlich einen sogenannten Bias, wie beispielsweise variierende Feuchtigkeit des Stückguts, in den Daten durch entsprechende Datentransformation in der Datenvorverarbeitung für den Lernprozess der KI im Vorfeld zu verringern. So könnte man beispielsweise nach einem Regenguss auf im Freien gelagertes Material unterschiedliche Feuchtigkeitsanteile in Abfällen durch entsprechende Transformation in einen normierten bzw. sozusagen trockenen Datenraum herausrechnen, bevor sie zu Fehlklassifikationen im KI-Modell führen.
Fazit
Genau diese schwer zugänglichen Zusammenhänge zwischen unterschiedlichen Anlagenteilen helfen Prozesse zu optimieren und Systemparameter dynamisch an sich verändernde Bedingungen, wie die sich im Prozess wandelnde physikochemische Beschaffenheit des Inputmaterials einer Produktionsanlage, anzupassen. Die ersten Schritte in der Hyperspektralen Bildverarbeitung und in der sensorgestützten Sortiertechnik sind damit getan.
www.evk.biz