
Die industrielle Bildverarbeitung (Machine Vision) übernimmt im Automatisierungsumfeld von Produktionsunternehmen unterschiedliche Aufgaben: Beispielsweise lassen sich damit sehr unterschiedliche Objekte entlang der gesamten Prozesskette identifizieren, zuordnen und nachverfolgen. Die Erkennung kann dabei sowohl aufgrund äußerer Merkmale als auch über aufgedruckte Datacodes oder mittels OCR-Verfahren (Texterkennung) erfolgen. Darüber hinaus optimiert und automatisiert Machine Vision das Handling von Produkten und Bauteilen: Die Position von Werkstücken lässt sich so bestimmen, dass diese zur Bearbeitung ausgerichtet werden können. Zudem können Roboter und Cobots Objekte wahrnehmen und greifen. Und nicht zuletzt lässt sich die Kollaboration zwischen Menschen und Maschinen sicherer und effizienter gestalten. Denn durch kontinuierliche Überwachung der Abläufe werden gefährliche Situationen und Kollisionen zwischen den Beteiligten vermieden.
Defekte Teile finden
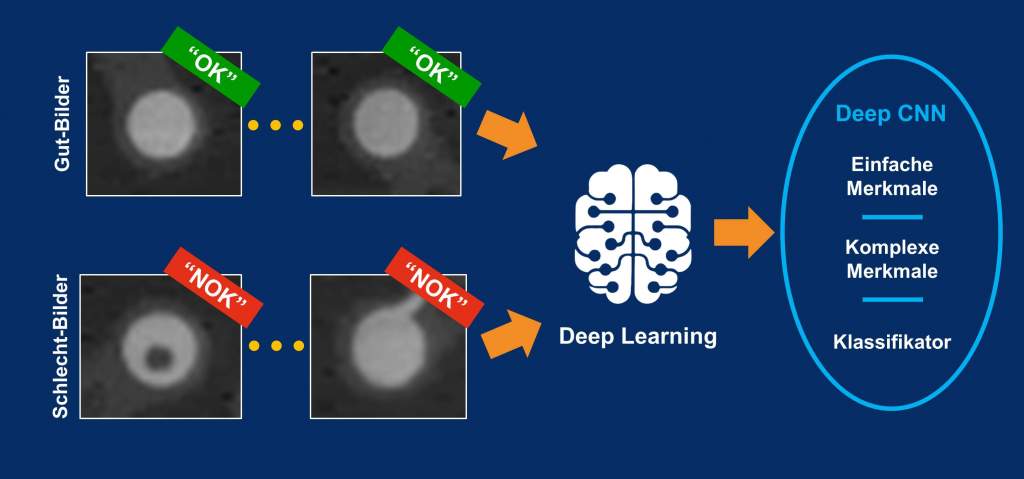
Auch bei der Automatisierung der Fehlerinspektion spielt die industrielle Bildverarbeitung eine Rolle. So vergleicht die Machine-Vision-Software anhand der aufgenommenen digitalen Bilddaten permanent den Ist- und Sollzustand der zu prüfenden Objekte und erkennt Anomalien. Dadurch lassen sich defekte Teile automatisiert aussortieren. Noch robuster funktioniert dieser Prozess mit KI-Technologien – insbesondere wenn Deep Learning zum Einsatz kommt, das auf Convolutional Neural Networks (CNNs) basiert. Die Integration solcher KI-Algorithmen in die Bildverarbeitungssoftware hebt die automatisierte Fehlererkennung auf eine neue Stufe.
Deep Learning
Mittels Deep Learning werden die von den Bildeinzugsgeräten aufgenommenen digitalen Bilddaten umfassend ausgewertet. Dabei lernt die Machine-Vision-Software im Rahmen eines Trainings, welche Eigenschaften typisch für eine bestimmte Objektklasse sind. So können die Bilddaten einer spezifischen Klasse zugeordnet werden. Dies ermöglicht die automatische Klassifizierung von Gegenständen und Fehlern. Zu beachten ist jedoch, dass der Deep-Learning-basierte Trainingsprozess eine durchdachte und gute Vorbereitung erfordert. Es muss zunächst eine große Menge an verwertbaren Bilddaten erzeugt und gesammelt werden. Im nächsten Schritt werden die Bilder gelabelt, also mit einem digitalen Etikett versehen. Dieses markiert eine spezifische Objekt- oder Fehlerklasse. Erst nach dem Labeling-Prozess kann das zugrundeliegende, neuronale Netz mit den jeweiligen Bildern trainiert werden. Der Labeling-Prozess ist dabei mit großem Aufwand verbunden. Denn je nach individueller Anwendung sind zwischen 150 und 300 Trainingsbilder pro Fehlertyp erforderlich. Wichtig ist, dass diese die Objekte mit den zu erkennenden Defekten in verschiedenen Erscheinungsformen zeigen – sogenannte ‚Schlecht-Bilder‘. Von diesen sind jedoch oft nicht genug vorhanden. Zudem sind die möglichen Fehlertypen in ihrer konkreten Erscheinungsform vorher meist nicht bekannt. Die Beschaffung und das Labeling solcher Bilder können also einen hohen Ressourceneinsatz erfordern, der oft nicht rentabel ist.
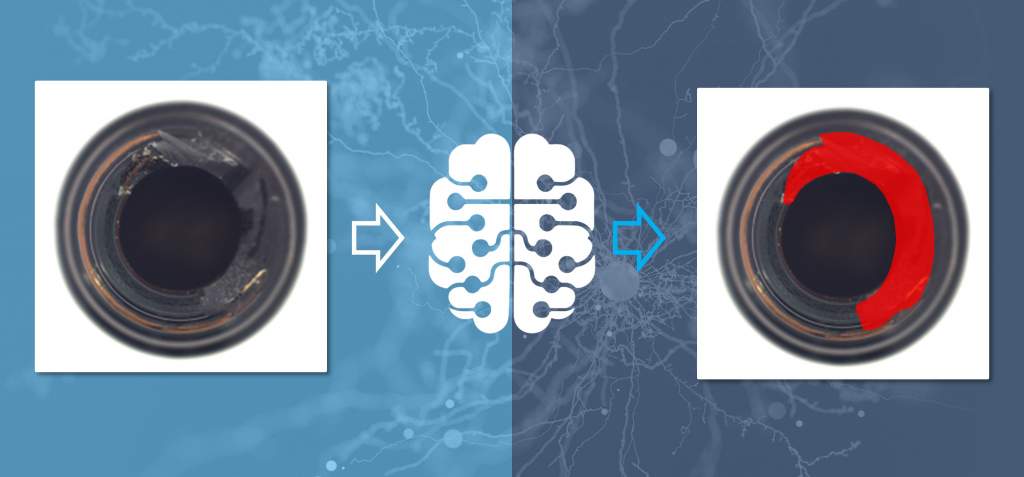
Anomaly Detection
Abhilfe kann die Anomaly-Detection-Technologie schaffen, die in die Machine-Vision-Standardsoftware MVTec integriert ist. Anomaly Detection benötigt für die Defekterkennung nur noch sogenannte ‚Gut-Bilder‘, also solche, die den jeweiligen Gegenstand in fehlerlosem Zustand zeigen. Diese lassen sich einfacher erzeugen als ‚Schlecht-Bilder‘, was Zeit und Kosten spart. Ein weiterer Vorteil: Die Daten müssen zudem nicht gelabelt werden und es sind deutlich weniger Bilder für das Training erforderlich. So genügen bereits 20 bis maximal 100 Bilder, um passable Erkennungsergebnisse zu ermöglichen. Die möglichen Fehler müssen zudem nicht im Vorfeld bekannt sein, da die Software-Algorithmen Abweichungen vom trainierten Soll-Zustand erkennen.