
Grundlage für KI-Applikationen
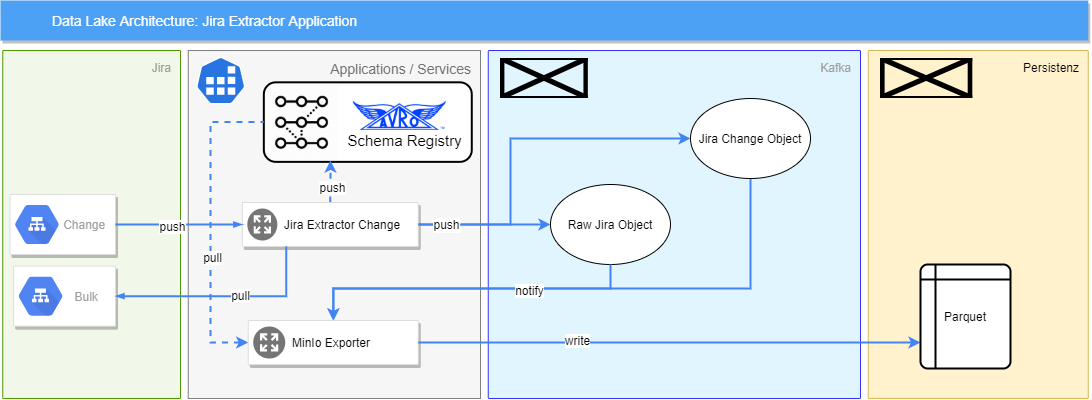
MediFox hat nun die Möglichkeit, historische Rohdaten aus ihrem Data Lake zu nutzen, um eine Transformation in ein strukturiertes Format zu definieren und somit eine Grundlage für industrielle KI-Anwendungen geschaffen. Da keine Daten verloren gehen, können jederzeit auch Anwendungsfälle umgesetzt werden, an die beim Design des Data Lake noch niemand dachte. Neue Datenquellen lassen sich durch ein flexibles Design in Form einer servicebasierten Architektur hinzufügen. Ganz praktisch hat die Firma eine Anwendung geschaffen, die die Abwanderungswahrscheinlichkeit ermittelt, sobald genug Daten für eine Vorhersage vorliegen.
www.agile-im.de