
Plausible Daten
Eine Herausforderung für Prognosemodelle im Behältermanagement besteht in der Abhängigkeit des Behälterflusses zum zugrundeliegenden Produktionsgeschehen. Die Daten müssen ein entsprechende Erklärkraft haben und beispielsweise die erwarteten Ausgangsbuchungen der kommenden Woche mit ausreichender Genauigkeit prognostizieren. Und neben dem dynamischen Produktionsgeschehen kommen kurzfristige Faktoren wie Verschmutzung der Behälter oder Verspätungen der Transporte hinzu. Eine weitere Herausforderung stellen zu geringen Datenmengen dar. Aber dabei kann Machine Learning in Kombination mit Clusteringverfahren helfen, indem ähnliche Daten zusammengefasst werden, was den verfügbaren Datensatz erweitert.
Die im Projekt erfolgreich erprobten Anwendungsfälle erstrecken sich über:
- die Prognose von Buchungen und dem Bestand,
- die Anwendung von Klassifizierungs-, Clustering- und Prognosemodellen zur Bewertung von Kontenpartnern bzw. Lieferanten,
- dem Einsatz von Sentimentanalyse- und Textauswertungstools zur verbesserten Reaktion auf Anliegen der Systemnutzer.
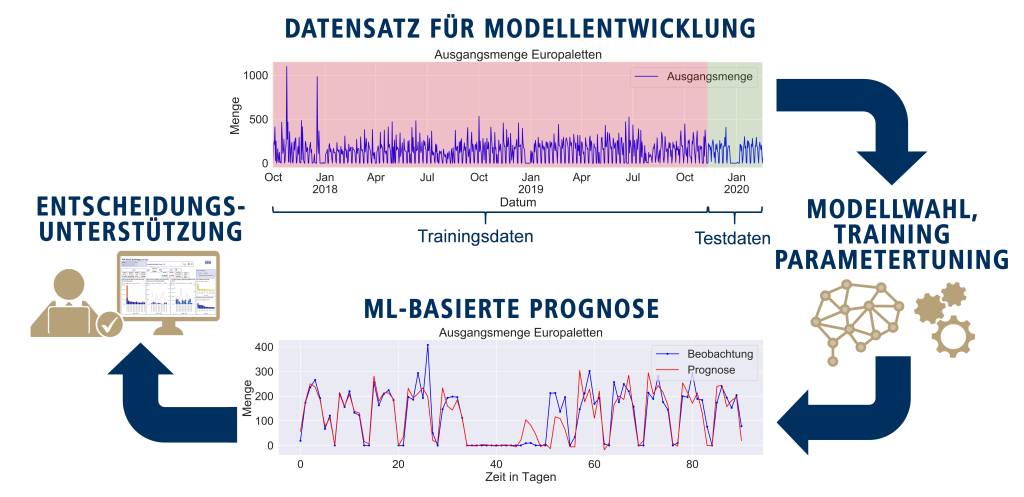
Die Vorhersage ausgewählter KPI (siehe Bild) und damit die Ableitung einer Entscheidungsunterstützung funktioniert wie folgt: Ausgehend von einem Set an Trainingsdaten wird ein geeignetes Modell ausgewählt und auf Basis von Parametervariationen konfiguriert. Anschließend wird zur Validierung ein Verlauf der KPI durch Einbezug von multivariaten Einflussgrößen durch die ML-basierte Prognose vorhergesagt und mit den tatsächlichen Referenzdaten verglichen. Die Daten können dann in einem Dashboard angezeigt werden, und bieten Informationen zur Entwicklung der Kennzahlen.
Daten sammeln mit RFID
Für Machine Learning und KI gilt, je größer die Datenmenge desto genauer die Prognose. Der Einsatz von ML-Lösungen hängt darüber hinaus von der Systemlandschaft vor Ort sowie der verwendeten Sensorik, etwa RFID, ab. Die Implementierung von serialisierten Ladungsträgern, welche mit Barcode oder mit RFID Transpondern ausgestattet sind, ermöglichen beispielsweise eine automatisierte Datenerfassung. Durch das Behältermanagementsystem BinMan® als Verwaltungsschicht der aufgenommenen Daten kann der zunehmende Trend der Automatisierung durch die Integration von RFID-Technologie auch für weitere Auswertungsfunktionen wie der Optimierung von Transport und Distribution durch Machine-Learning-Anwendungsfälle wie der Routenplanung zur Verfügung gestellt werden. Für eine erfolgreiche Implementierung ist neben dem domänenspezifischen Wissen zudem auch Data-Science-Knowhow gefragt.
Der Weg in die VUCA-Welt
Der Einsatz von KI ist für die Logistikbranche von großer Bedeutung, stellt Unternehmen jedoch vor viele Herausforderungen. Um für die zukünftigen Anforderungen einer ‚VUCA- Welt‘ (Volatility, Uncertainty, Complexity, Ambiguity) vorbereitet zu sein, sind entscheidungsintelligente Algorithmen mit maschinellen Lernverfahren eine Voraussetzung.