
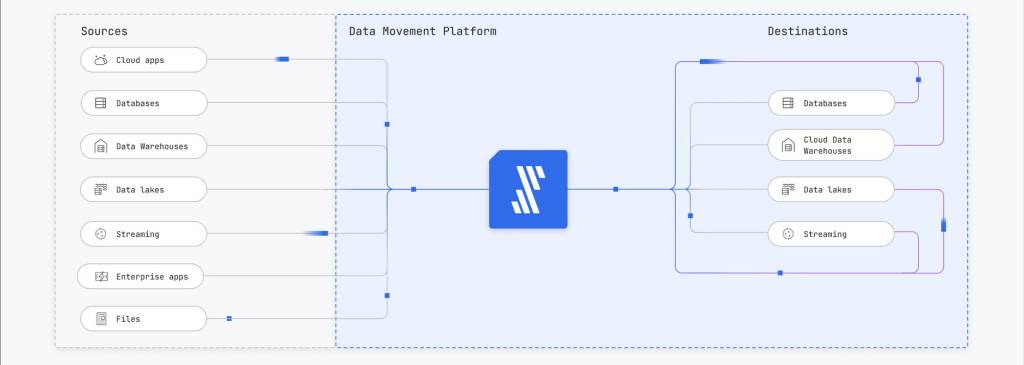
Viele Unternehmen nutzen primär ein On-Premise Data Warehouse. Doch Teile des Data Stacks werden zunehmend in Cloud-basierte Data Warehouses oder in Data Lakes verlagert, wenn dort kostengünstige Rechenleistung in großem Umfang zur Verfügung steht. Die meisten Daten liegen jedoch immer noch in Systemen, die ihre Daten nicht ausreichend für Analysen bereit stellen können. Es ist keineswegs trivial, die Daten aus den verschiedenen Systemen an einem zentralen Ort zu konsolidieren. In vielen Unternehmen erstellen Datenspezialisten hierfür eigene Datenpipelines. Das kann extrem zeitaufwendig sein und nicht selten fallen die Pipelines aus, etwa weil es API-Änderungen an der Quelle gab. Zudem liegen die Daten oft in mangelhafter Qualität vor und kommen mit zeitlicher Verzögerung am Bestimmungsort an.
Herausforderung
bei ERP-Daten
Eine besondere Herausforderung stellt der Zugriff auf Daten dar, die in SAP-Systemen gespeichert sind. 99 Prozent der Unternehmen kämpfen hier mit Problemen bei der Datenintegration: Für 65 Prozent ist schon der Zugang zu den ERP-Daten schwierig. Das hat eine kürzlich von Dimensional Research und Fivetran durchgeführte weltweite Umfrage unter mehr als 400 ERP-Spezialisten und -Spezialistinnen ergeben. Bislang war die Integration dieser ERP-Daten kaum ein Problem, weil diese nur gezielt für spezifische Zwecke exportiert wurden. In Zeiten hoher Volatilität, fragiler Lieferketten und dem steigenden Druck, die OEE (Overall Equipment Effectiveness) zu erhöhen, ist es zunehmend wichtig, auch ERP-Daten in Echtzeit nutzen zu können.
Unternehmen, die dies mit eigenen Datenpipelines realisieren, müssen immense Datenmengen verarbeiten, die zudem stetig größer werden. Zudem müssen die Datenpipelines an Änderungen des Systems oder neue Produktlinien angepasst werden, damit keine veralteten, unzuverlässigen Daten entstehen. Diese manuellen Anpassungen kosten viel Zeit.
Automatisierung
statt Handarbeit
Eine Alternative ist eine automatisierte und skalierbare Datenpipeline, wie sie Fivetran mit seinen High-Volume-Agent (HVA)-Konnektoren entwickelt hat. Diese Konnektoren des auf Datenbewegung spezialisierten Unternehmens basieren auf einer logbasierten Change-Data-Capture (CDC)-Technologie. Bei dieser Replikationsmethode werden die Daten mit einem Agent direkt aus den Protokollen des Quellsystems ausgelesen. So können sich auch große Datenmengen mit geringer Latenz und mit geringen Auswirkungen auf die Quelle verarbeiten lassen. Anbieter Fivetran verspricht damit den Zugriff auf exakte und granulare Daten nahezu in Echtzeit.
Neben den HVA-Konnektoren bietet das Unternehmen vorkonfigurierte und und verwaltete Konnektoren für über 450 Datenquellen. Sie sollen innerhalb weniger Minuten bereitstehen, um Daten aus den Quellen sowohl in Cloud- als auch in On-Premise-Umgebungen zu bewegen und zu zentralisieren. Die Konnektoren können sich automatisch an Änderungen der Quell-APIs und -Schemata anpassen, um die manuelle Pflege zu ersetzen.
Beispiele aus der Praxis
Das Beispiel Schüttflix demonstriert, wie das in der Praxis funktioniert: Das Logistik-Start-up will Lieferanten von Baumaterialien, Spediteure und Käufer über eine B2B-Plattform verbinden und so die Transaktionen beschleunigen und somit Kosten senken. Hierfür baute Schüttflix einen sogenannten Modern Data Stack auf. Dieser besteht im Wesentlichen aus HubSpot- und MySQL-Datenbanken sowie Google Sheets. Von hier werden Daten mit Konnektoren von Fivetran in Google BigQuery zentralisiert.