

Hauptunterscheidungsmerkmal zu einem herkömmlichen IPCs ist die Tatsache, dass die Jetson-Xavier-Module über eine integrierte GPU verfügen, weshalb das System ausreichend Leistung für die Verarbeitung anspruchsvoller KI-Anwendungen hat. Das Modul ist unter anderem mit Video De-/Encoder sowie Deep Learning Beschleunigern (DLA) ausgestattet. Mit einer Betriebstemperatur von -10 bis 50°C, passiver Kühlung und geringem Stromverbrauch ist es für den Edge-Betrieb ausgelegt.
Hardware
Der Jetson Xavier ist in zwei Varianten erhältlich. Die kleinere Version verfügt über 8GB RAM bei einem Speichertakt von 1.333MHz, sechs ARM sowie 364 Volta GPU/48 Tensor-Kernen, während der große Bruder über 16GB bei 2.133MHz Speichertakt und acht ARM sowie 512GPU/64 Tensor-Kerne verfügt. Im Hinblick auf die effektive Leistung für KI-Anwendungen bietet die 16GB-Version ungefähr doppelt so viel Rechenleistung wie die 8GB-Version. Beide Versionen verfügen über 32GB internen Speicher, der neben dem Betriebssystem ca.16GB freien Speicherplatz für zusätzliche Anwendungen bereit hält. Beide Versionen sind mit einem HDMI, 2x RJ45 GbE-Anschlüssen, 2x USB 2.0 sowie 2x USB 3.0-Anschlüssen an der Vorderseite ausgestattet, sowie 2x COM-Ports sowie 16 DI/DO-Anschlüsse. Unter der Rückseite befinden sich weitere 3x USB 2.0-Anschlüsse auf der Platine, ein zusätzlicher COM-Port, eine 5V Stromversorgung sowie ein NanoSim-Slot.
Das Gehäuse verfügt über Platz für ein 2,5-Zoll Laufwerk, während das Modul über einen SATA-Anschluss sowie über einen M2 und einen Mini-PCI-Express-Steckplatz verfügt. Für die Unterstützung von zwei PCI-Express-Karten in voller Größe kann das Gehäuse mit dem Erweiterungsmodul MIC-75M20 ausgestattet werden. Über die iDoor Blende kann das System auch mit einer Vielzahl von Mini-PCIe-basierten Erweiterungen (Wifi, LTE, industrielle Feldbusadapter…) bestückt werden.
Das System wird mit Linux Ubuntu 18.04 und dem ‚Jetpack‘ Softwarepaket ausgeliefert. Dieses enthält die Nvidia-Bibliotheken und -Tools zur Beschleunigung von Deep-Learning-Anwendungen. Technisch bietet die Umgebung die gleichen Annehmlichkeiten wie ein GPU-basiertes PC-System. Die Bereitstellung von neuronalen Netzwerken, die auf einem PC oder in der Cloud trainiert wurden, ist daher unkompliziert. Obwohl es technisch möglich ist sogar neuronale Netze auf dem MIC-730AI zu trainieren, ist das System grundsätzlich für die Ausführung ausgelegt. Netzwerke können prinzipiell nativ mit Python ausgeführt werden. Um jedoch die beste Leistung zu erzielen, empfehlen wir C++ in Kombination mit Netzwerkoptimierung zu verwenden. Die Nvidia-Inferenzbibliothek TensorRT ist im Jetpack bereits vorinstalliert.
Test 1: Massenverarbeitung
Das erste Testszenario ist ein anspruchsvoller Anwendungsfall für die Massenverarbeitung mit geringer Latenzzeit. Typischerweise findet man diese Art der Verarbeitung z.B. in Fahrzeugen oder in einigen industriellen Anwendungsfällen. Das Setup ist:
– MIC-730AI
– zwei Basler ACE Industrie-Kameras mit einer Auflösung von 1.920×1.200 Pixel
– GPU-basiertes Stereokamerasystem für die 3D-Rekonstruktion
– Middleware-Software (Publish / Subscriber Message Bus)
– Visualisierung mit 5 bis 10 Millionen 3D-Punkten/s
– Deep Learning-basierte Objekterkennung mit einer Auflösung von 960×600 Pixel
– Visualisierung der Objekterkennung
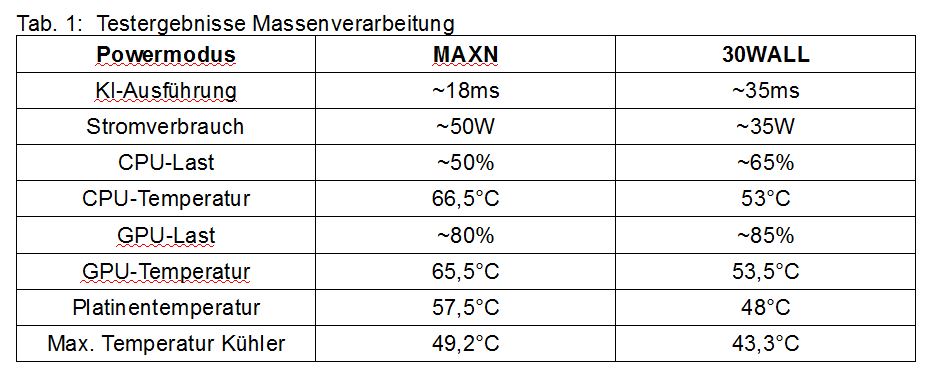
In dieser Konfiguration verarbeitet das System 625MB/s Daten, wobei die verfügbare Speicherbandbreite ungefähr zu 40 Prozent ausgelastet wird. KI-Algorithmen werden hauptsächlich auf der GPU verarbeitet. Daher beträgt die Auslastung aller CPU-Kerne nur 50 Prozent, während die GPU im Durchschnitt mit mehr als 80 Prozent ausgelastet ist. Evotegra hat das MIC-730AI in zwei verschiedenen Leistungsmodi getestet. Durch die Anpassung der verwendeten CPU-Kerne sowie die Taktfrequenzen von CPU und GPU kann mit den Leistungsmodi der Stromverbrauch auf 10, 15 oder 30W begrenzt werden. Im MAXN-Power-Modus arbeiten sowohl CPU als auch GPU mit maximaler Geschwindigkeit. Dabei wird allerdings keine Obergrenze für den Stromverbrauch garantiert. Um das System auszulasten und die Wärmeableitung des passiven Kühlsystems zu validieren, haben wir in diesem Modus einen 24h-Belastungstest durchgeführt. Der 30W ALL-Modus ist ein Modus, der den Stromverbrauch unter Verwendung aller acht ARM-Kerne auf 30W begrenzt.
Testergebnisse (Tab. 1): Während der Tests in beiden Modi verarbeitete das System insgesamt mehr als 100TB Daten. Bei Raumtemperatur erreichten sowohl die CPU als auch die GPU bis zu 66°C und erwärmten den passiven Kühler auf maximal 50°C. Dies lag jedoch weit unter der empfohlenen maximalen GPU-Temperatur von 88°C. Das System arbeitete zu jeder Zeit stabil.
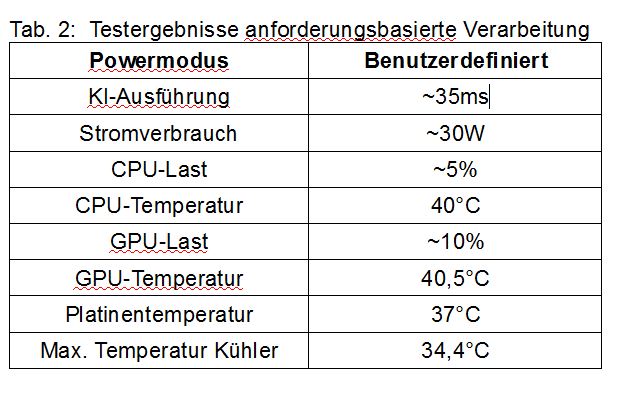
Test 2: Anforderungsbasierte Verarbeitung
In diesem Szenario wird das System in einem typischen industriellen Anwendungsfall getestet. Es empfängt die Daten über die Netzwerkschnittstelle (C++). Ziel ist es, die Daten mit der geringstmöglichen Latenz zu verarbeiten (Deep-Learning-basierte Objekterkennung und -klassifizierung mit 1.024×1.024 Pixel). Um Energie zu sparen, wird selbst im Power-Modus MAXN der Takt für CPU und GPU bei geringer Last gedrosselt. Dadurch haben die ersten Bilder eine bis zu dreimal höhere Latenz, als die nachfolgenden Bilder. Während in den meisten Anwendungsfällen die Energiesparfunktionen unproblematisch sind, ist dies für die zeitkritische Verarbeitung kein erwünschtes Verhalten. Die Lösung ist einen benutzerdefinierten Energiesparmodus zu erstellen, der den GPU- und CPU-Takt auf ihre maximale Frequenz begrenzt.