Bediene die Maschine und entdecke Beiträge aus der Industrie.
Belohnung als
Anreiz zum Lernen
Bild: Fraunhofer-Institut IML
Bild: Fraunhofer-Institut IML
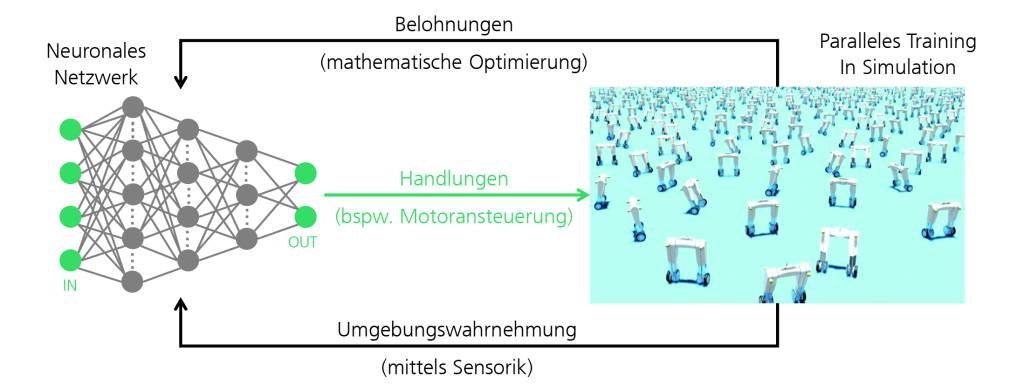
Wie sieht das Belohnungssystem für Roboter genau aus? @Interview_Grundschrift:Julian Eßer: Reinforcement Learning (RL) ist ein Gebiet des maschinellen Lernens, in dem Roboter lernen, Entscheidungen zu treffen, um belohnt zu werden. Ihr Ziel ist es, immer besser zu werden. In einem interaktiven Trainingsprozess lernt der Roboter, welche Handlungen ihn zum Ziel bringen, eine Aufgabe zu lösen und welche nicht. Das direkte Feedback belohnt oder bestraft den Roboter dabei für jede Handlung. So entsteht in diesem interaktiven Prozess im Roboter mit der Zeit ein trainiertes neuronales Netz – ähnlich, wie auch der Mensch durch Erfahrung lernt und dadurch Synapsen bildet. Der gesamte RL-Workflow ist also eine Art iterativer Lernprozess: Der Roboter nimmt seine Umgebung mittels Sensoren wahr und lernt, auf dieser Basis Entscheidungen zu treffen – eine natürliche und sehr ähnliche Perspektive, wie auch wir Menschen lernen! Das Belohnungssystem ist der wesentliche Kern des Trainingsprozesses. Auf dem Weg zur Lösung einer Aufgabe werden bestimmte Gütekriterien im Optimierungssystem für die Roboter definiert, wie z.B. Geschwindigkeit, Präzision oder Fehlertoleranz. Sämtliche Erfahrungen, die die Roboter im Laufe des Trainingsprozesses machen, werden dabei in Form eines neuronalen Netzes zur Wiederverwendung gespeichert. Befinden sich die Roboter ausschließlich im virtuellen Raum? @Interview_Grundschrift:Grundsätzlich können diese Methoden sowohl direkt auf den realen Robotern angewendet, als auch vorab in realitätsnahen Simulationen trainiert werden. Das Training im virtuellen Raum ist dabei zum Standard geworden. Denn die Vorteile liegen auf der Hand: reduzierter Arbeitsaufwand, erhöhte Sicherheit sowie ein beschleunigter Lernprozess. Dadurch, dass bei Experimenten mit den virtuellen Robotern keine Schäden am realen System entstehen, entfallen aufwändige Reparatur- und Wartungsarbeiten. Zudem werden auf den echten Robotern lediglich Strategien angewendet, die vorab in der Simulation geprüft wurden und die definierte Gütekriterien erfüllen – das macht sie sicherer. Noch dazu ist das Training in der Simulation skalierbarer: In der Realität steht nur eine begrenzte Anzahl Roboter zur Verfügung. In der Simulation jedoch können mehrere tausend Robotern gleichzeitig lernen und ihr Wissen teilen, so lernen sie auch voneinander. Das beschleunigt den Trainingsprozess der Roboter erheblich. Wie ist die Simulation auf tatsächliche Roboter zu übertragen? @Interview_Grundschrift:Nachdem die Roboter ihre Aufgaben in den virtuellen Lernumgebungen erfolgreich trainiert haben, werden die gelernten Strategien auf das reale Robotersystem übertragen – auch bekannt als Sim-to-Real-Transfer. Dabei werden die trainierten neuronalen Netzwerke auf den Roboter deployed und mit den entsprechenden Sensoren und Motoren des realen Systems verknüpft. Idealerweise ist der Sim-to-Real-Gap möglichst gering, damit die Roboter die trainierten Aufgaben in der realen Welt mit gleicher Performance ausführen können, wie in der Simulation. Es geht um exakte Simulationsmodelle der Roboter, was ihre dynamischen Eigenschaften und die Qualität der zur Verfügung stehenden Sensordaten betrifft oder wie die Motoren auf Ansprache reagieren. Findet das Training auf Basis solcher Simulationsmodelle statt, lassen sich die trainierten neuronalen Netze meist auch robust auf reale Robotersysteme übertragen.